Most people think AI metadata tagging is some magic black box that just “knows” what’s in your video. It’s not. Here’s what’s actually happening: computer vision models look at the frames, speech-to-text models listen to the audio and language models stitch it all into something useful, genre, objects on screen, scene types, spoken keywords, mood, cast, content ratings.
The old way meant someone on staff opened each video file and typed in a title, a description, a few tags. One asset at a time. Forever. AI flips that. It scans the catalog and writes structured metadata across thousands of titles while your team does something else.
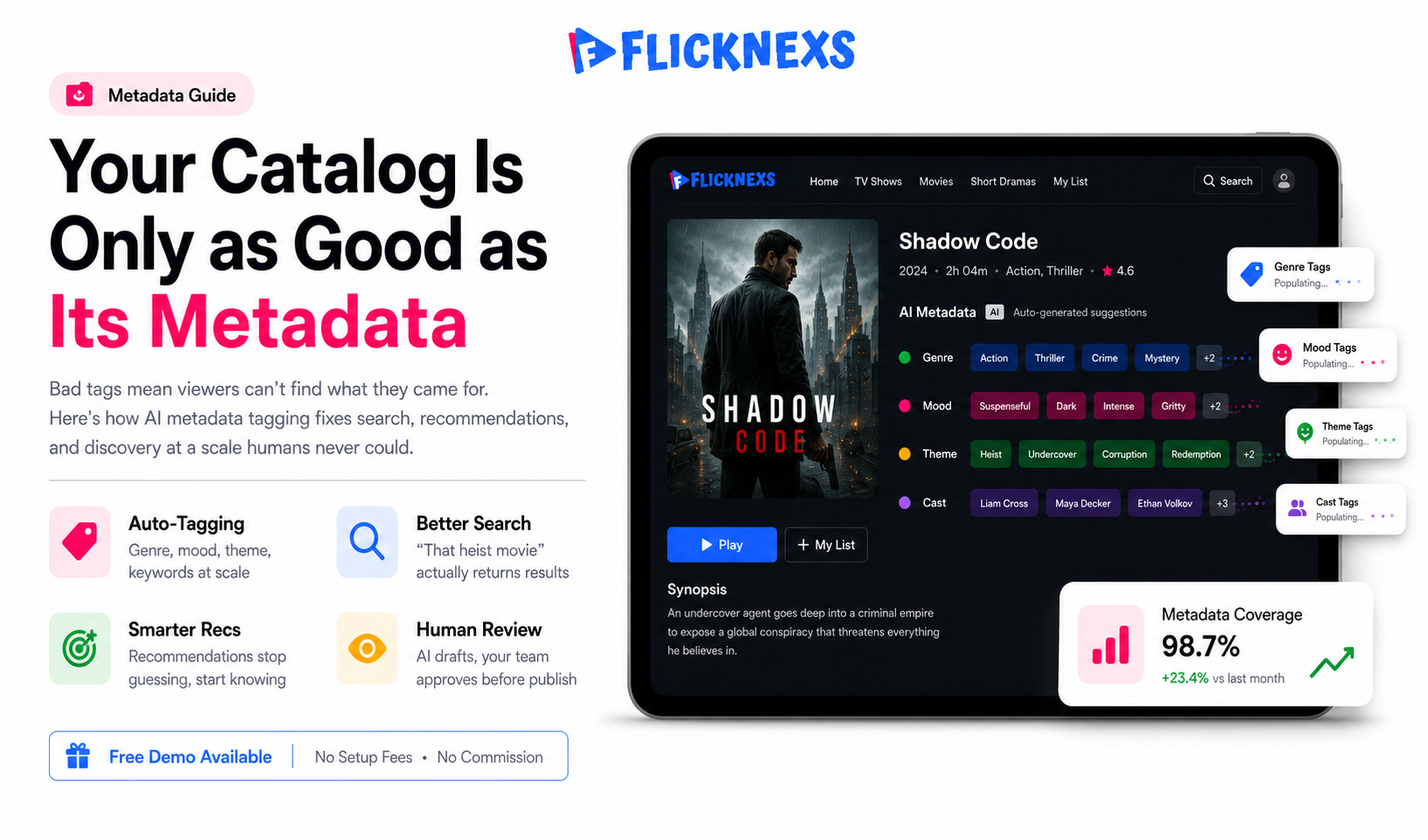
Why does this matter for an OTT or VOD library specifically? Because metadata is the thing your search and recommendation engines actually run on. Bad metadata means a viewer types “that heist movie with the British guy” and gets nothing. Good metadata generated at scale means onboarding new content goes faster search returns the right result and recommendations actually feel like they understand the viewer instead of guessing.
Think of it like a librarian who’s read every book in the building versus one who’s only skimmed the covers.The second one is just guessing based on the title. That’s the difference good metadata makes to your discovery surfaces.
The real payoff isn’t the metadata itself. It’s what it does downstream: viewers find the right title faster, which means they watch more and cancel less. That’s the whole game in streaming.
One catch worth naming directly don’t let this run fully blind. Treat it as assist-and-review. Let the models do the heavy lifting then have a human glance over the output before it goes live. AI gets a lot right and occasionally gets something embarrassingly wrong and you don’t want that surfacing on a live title page.
By the Flicknexs team. We build white-label OTT/VOD/IPTV streaming platforms, so this is written from hands-on streaming-platform experience.
If you run a streaming service of any meaningful size, your single biggest hidden cost is not bandwidth or encoding. It is the human time spent describing content. Metadata is what powers search, filtering, rows, recommendations and SEO. When it is thin or inconsistent, viewers cannot find what they came for and a catalog you paid to license or produce sits unwatched. AI metadata tagging goes straight at that problem. This guide explains what it actually does, where it helps, where it fails and how to roll it out without creating a mess you have to clean up later.
What AI metadata tagging actually does
The term covers several distinct techniques that usually run together in a pipeline. Each one looks at the video from a different angle and produces a different slice of metadata.

The three engines under the hood
Three different technologies are doing three different jobs here and conflating them is exactly why people get confused about what “AI tagging” actually means.
First layer: computer vision, watching the frames. It’s spotting objects, scenes, on-screen text, logos, faces, shot composition. This is the layer that tags a clip “beach, sunset, two people” or catches that a brand logo flashed up at 00:42. It only sees. It doesn’t understand context and it definitely doesn’t read a transcript.
Second layer: speech-to-text paired with NLP, listening to the audio. It transcribes the dialogue and narration, then mines that transcript for topics, named entities, keywords. This is the layer that catches the stuff visual tagging would never find. A documentary mentioning “monsoon,” “Kerala,” “fishing economy” gets tagged on those themes even if none of those words appear anywhere in the title or the visuals.
Third layer is where it gets interesting large language models, sitting on top of the other two and making sense of what they produced. Feed an LLM the transcript, the visual tags, whatever existing metadata you’ve got and it writes a clean synopsis, suggests a genre, proposes a content rating, generates descriptions that don’t read like a robot wrote them and cleans up messy tags into whatever controlled vocabulary your system uses.
Same way a sound engineer takes raw tracks from different microphones and mixes them into one coherent song, the LLM takes raw signal from vision and speech models and mixes it into metadata a human would actually write.
This synthesis layer is also the one that’s improved the most in the last couple of years. If you tried AI tagging back when it was just vision plus speech-to-text and walked away unimpressed that’s fair. But that’s not where the category is anymore and it’s exactly why this is worth a second look now.
The metadata it produces
- Descriptive: title suggestions, synopsis, genre, sub-genre, mood, themes, keywords.
- Structural: chapters, scene boundaries, intro/credit timestamps, highlight moments.
- People and rights: recognized cast, on-screen text, spoken language(s), candidate content ratings.
- Technical and editorial: dominant colors for thumbnail selection, sentiment, pacing, suitable audience segments.
Why it matters for discovery
Discovery is a metadata problem disguised as a product problem. Every recommendation row, search result, “more like this” shelf, and filter chip is ultimately querying metadata. If your catalog has uneven tagging, where some titles are richly described and others have a one-line synopsis and no genre, your recommendation engine has nothing consistent to reason over and search returns gaps.
Rich, consistent metadata improves three things at once. Search becomes recall-friendly, because a viewer who types a theme an actor or even a half-remembered line of dialogue can land on the right title. Recommendations improve, because similarity models have dense feature vectors to compare. And catalog SEO improves, because every title page carries unique, descriptive, structured text that search engines can index. Thin metadata starves all three.
Manual vs AI tagging: an honest comparison

AI is not a clean replacement for editorial judgment. The right model is augmentation. The table below reflects what we typically see across catalogs, given as honest ranges rather than precise figures, because real numbers depend heavily on content type and team skill.
| Dimension | Manual tagging | AI tagging (with human review) |
|---|---|---|
| Speed per asset | Minutes to tens of minutes | Seconds to a few minutes of compute, plus brief review |
| Consistency | Varies by person and fatigue | Highly consistent against a fixed vocabulary |
| Cost at scale | Grows linearly with catalog size | Mostly compute; scales far better |
| Nuance and editorial taste | Strong | Improving, but still needs a human eye |
| Rights/compliance accuracy | High when staff are trained | Good for first pass, must be verified |
| Handling huge backlogs | Often never gets done | Feasible to clear in a planned sweep |
The pattern is clear. AI wins decisively on speed, consistency and backlog clearance, while humans stay essential for taste, edge cases and anything with legal or compliance weight. Treat AI output as a strong draft that a person approves, especially for content ratings and rights-sensitive fields.
How to roll it out without creating a mess
Step 1: Define your taxonomy first
Here’s the mistake almost everyone makes on their first AI tagging rollout: they turn the model loose before deciding what words they’re allowed to use. Write down your controlled vocabulary first. The canonical list of genres, moods, themes, audience segments your product actually runs on. Do this before you tag a single video.
Skip that step and let the AI invent tags freely and you’ll end up with “thriller” and “suspense-thriller” all meaning the exact same thing in your database.That’s how your rows and filters quietly fragment under you.
The fix is simple to state and easy to skip anyway: give the model your taxonomy and tell it to map to the closest existing term. Anything that genuinely doesn’t fit gets flagged for a human, not invented on the spot as a brand new label.
What makes this particularly nasty is that the drift never announces itself. There’s no error message, no alert. It just shows up six months later as a “Thrillers” row sitting next to a “Thriller” row, eleven titles in one and nine in the other and now nobody on the team can tell you which one merchandising is actually supposed to be editing.
Step 2: Run a pilot on a representative slice
Pick 50 to 100 titles that span your genres and production qualities. Run the pipeline, then have an editor review the output and score it. You are looking for the accuracy rate per field. Vision tags are often very reliable, while subjective fields like mood need more correction. This tells you which fields you can trust on auto-publish and which ones need mandatory review.
Step 3: Set confidence thresholds and a review queue
Good systems return a confidence score per tag. Auto-accept high-confidence tags for low-risk fields and route low-confidence or high-risk fields (ratings, cast names, rights) to a human review queue. This keeps the speed benefit while containing the failure modes.
Step 4: Backfill the catalog, then tag on ingest
Run a one-time sweep across your existing library to fix the long tail of poorly described titles, then wire tagging into your ingest pipeline so every new upload is tagged automatically at the point of entry. The ingest hook is where the ongoing savings actually live. Skip it and you are back to a manual backlog within a quarter, because new content arrives faster than anyone wants to admit.
Step 5: Measure discovery, not just tag counts
More tags was never the point. More discovery is. Track search success rate, click-through on your recommendation rows, watch-time on titles that used to sit buried at the bottom of the catalog, both before and after you turn tagging on. If those numbers move, it’s working. If only your tag count goes up and nothing else budges, you haven’t improved discovery. You’ve just added noise with extra steps.
Common pitfalls to avoid
Hallucinated facts. An LLM will confidently hand you a cast member who was never in the film or a plot detail that doesn’t exist. It says this with the same tone it uses for things that are actually true and which is exactly the problem. Never auto-publish a name or a factual claim without a human checking it first. Ground the model on the transcript and whatever existing data you’ve got and treat everything outside that as a suggestion, not a fact.
Bias in vision models. Facial recognition and demographic inference get things wrong and in plenty of jurisdictions that’s not just an accuracy problem. It’s a legal one. Be careful with anything that identifies or categorizes people and check your local regulation before you flip that switch on.
Tag sprawl. Skip the controlled vocabulary and you’ll have thousands of near-duplicate tags within months and navigation gets worse instead of better. Constrain the model. This isn’t optional.
Language gaps. Speech-to-text accuracy varies by language and accent. For multilingual catalogs, validate transcription quality per language before you trust the downstream tags. This connects naturally to localization work: accurate transcripts also feed AI subtitling and auto-captioning and even AI dubbing, so good metadata ends up being a shared foundation across your whole AI stack.

Where tagging connects to the rest of your catalog
Metadata isn’t some isolated feature sitting off to the side. It’s the connective tissue holding your entire AI-driven catalog together and once you see that, you start noticing the same data showing up everywhere.
Take scene-detection and dominant color data. You generate it to tag a title, sure. But that same data is also what drives AI-generated thumbnails and trailers, because picking a good thumbnail and tagging a strong scene are the same underlying question which moments in this video actually look good? You’re not building two separate systems. You’re asking one system the same question twice.
Transcripts work the same way.Genre and mood tags power recommendation rows. Build the metadata layer well and every other AI feature you add gets cheaper and better, because they all read from the same enriched foundation. That compounding effect is the real strategic argument for investing here first.
If you want to see how automated tagging and the surrounding AI tooling fit into a managed streaming platform, our platform features page lays out what ships out of the box versus what you configure.


Leave a Reply